产品定位
鲁班仿真加速系列产品覆盖物理仿真求解器、控制系统仿真求解器与硬件加速算法库,致力于打造下一代科学计算求解引擎,追求科学计算加速极限,为仿真驱动的智能设计奠定充足的数据基础:
- 物理仿真求解器:面向结构、流体等多物理场问题,提供高精度、高并发的求解能力,显著缩短工程迭代周期。例如,鲁班系统最新GPU非线性力学求解器性能提升数十倍(多并发求解通量提升可达100倍)。
- 系统仿真求解器:利用创新算法 + 硬件加速技术,构建了一批高性能的频域分析、矩阵分解、ODE求解器等工具,面向复杂控制系统的频域与时域仿真加速。
- 软硬件加速运行时(Runtime):集成分布式计算、CPU、GPU、PTX 指令加速等技术,为各类仿真求解提供统一的高性能运行时支撑。

行业趋势分析
算得更快是仿真求解器开发的永恒追求,更快意味着更短的研发周期、更低的服务器成本,
更充分的“虚拟测试”验证,更快的仿真叠加AI技术将带来更多的可能性!
随着AI产业的爆发,越来越多的开发者开始接触并掌握GPU加速技术。在仿真领域,利用GPU加速数值求解的理念,早在十多年前便由少数行业先行者开展探索,其中很多还是我们国内的教授和专家。彼时,GPU生态尚不完善,专业人才稀缺,加之主流商软也缺少相关进展及报道,行业先行者能够一直坚持研究属实不易。近年来,得益于高性能计算(HPC)硬件与软件栈的快速发展,主流商业仿真软件逐渐推出了具备显著加速效果的GPU版本求解器,已逐步被更多工程师和企业认可并采用。
开发一款科学计算求解器,本身就是一项跨学科、系统化的工程,至少需要同时应对三大挑战:
数学与物理原理(算法层面):涉及偏微分方程(PDE)、数值稳定性、迭代收敛性、稀疏矩阵、非线性求解等核心技术。
工业工况与工程适配(行业层面):不同行业的物理模型、离散方法、边界条件、载荷和材料特性差异极大,需要求解器在保持精度的前提下具备高度的适应性和可扩展性。
- 现代软件工程与架构设计(软件层面):包括跨平台支持、模块化架构、内存管理、并行任务调度、I/O性能优化以及可视化与后处理接口。
开发一款GPU大幅加速的科学计算求解器则更具挑战。相比CPU,GPU在理论上具备更强的浮点运算能力(TFLOPS级别)和更大的内存带宽(TBps级别),这使其在处理高度并行、数据密集型的数值计算时有天然优势。然而,这种优势并非无条件释放:
算法限制更多:许多传统为CPU优化的算法在GPU上并不能直接高效运行,需要重新设计数据结构和并行策略(如从稀疏矩阵逐行存储转向块压缩格式,减少访存开销)。
- 内存访问模式要求更严苛:GPU高带宽的前提是访问模式连续且协同,非对齐或随机访问可能严重拖慢速度。
通信与扩展的瓶颈:在多GPU或GPU-CPU混合计算场景下,PCIe/NVLink传输延迟、节点间通信效率成为影响可扩展性的关键因素。
数值精度与稳定性挑战:GPU硬件在单精度和半精度上性能更强,但科学计算通常依赖双精度运算,需要很多特殊处理。
因此,在GPU求解器的研发过程中,不仅要深刻理解数值计算原理,还要结合GPU架构特性对算法进行针对性重构与优化。同时,需要构建高效的异构计算框架,充分利用CPU与GPU各自的优势,实现任务分工与数据流的高效协同。这不仅是一次计算平台的迁移,更是一次算法设计理念和软件工程方法的整体升级。
行业GPU高速求解实测
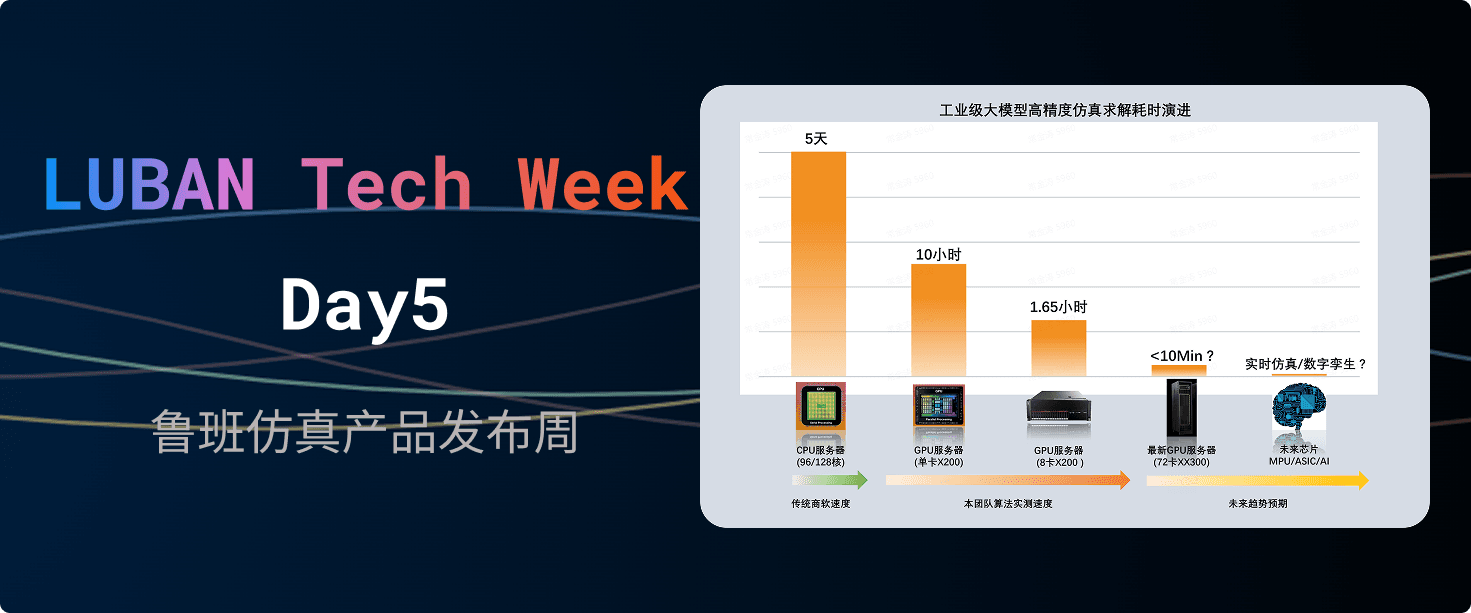
如上文所述,开发一款能够在GPU平台上实现大幅加速的科学计算求解器具备相当的难度,需要在算法重构、数据布局优化、并行调度以及硬件特性适配等方面进行系统性突破。然而,这一目标并非遥不可及。
在与行业一线客户长期合作的过程中,我们接触到一批追求卓越、持续探索新技术的领先企业与研发团队。他们在产品设计和工程分析中积极引入GPU加速,并与我们共同对多个最新的求解器、最新的计算硬件进行了深入测试与验证。我们发现自2024年以来,有多款国际主流商业仿真软件最新的GPU版本加速比大幅超越常规预期,尤其是在计算流体力学(CFD)领域表现突出,下图展示了某次流体仿真求解的实测数据,采用单节点对比,GPU节点比CPU节点加速超过两个数量级:
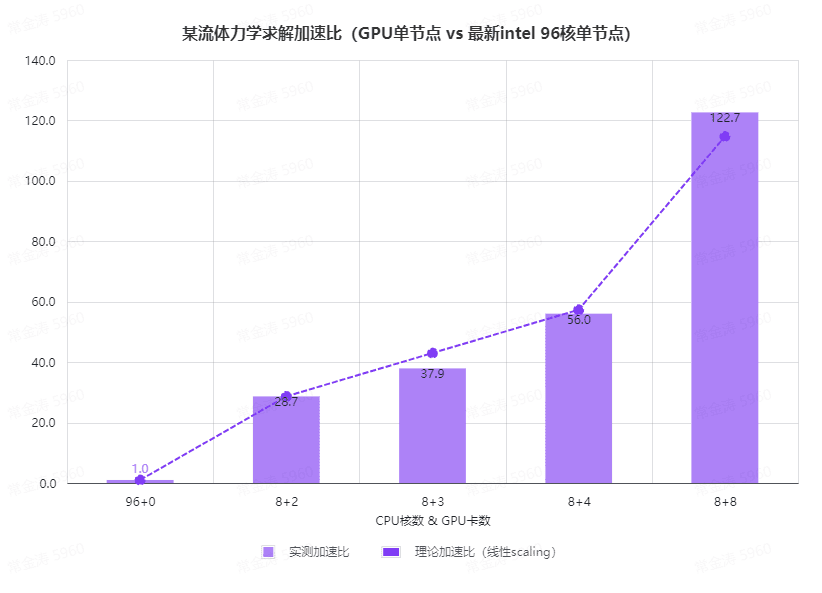
备注:本测试例单元规模亿级。由于模型规模过大单卡显存不足,故上述GPU数从2开始(8CPU+2GPU)。
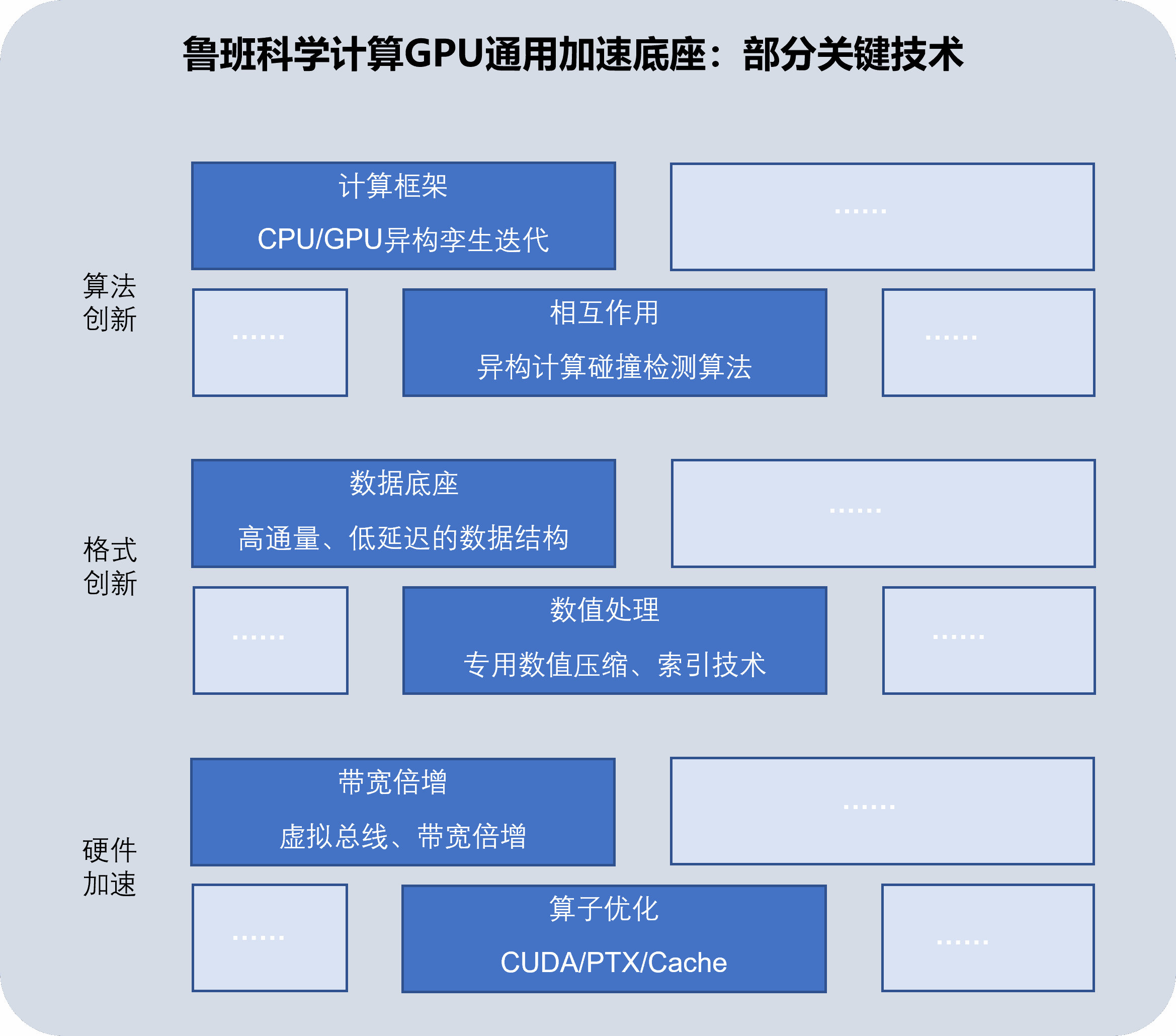
鲁班科学计算GPU通用加速底座
如果说前20年CAE软件行业已然趋于成熟,近年来涌现的GPU技术、AI技术,则可能有重塑整个行业、加速爆发的潜力。经过长期调研,我们认为本行业“冰山下”的进展其实是日新月异的,因此,自研软件的性能目标不能刻舟求剑,反而要更加“激进”,才有机会追上国际顶尖的水平。
目前主流商软在流体、电磁等领域已经发布了多个完全GPU计算(Fully GPU Compute)的新求解器,而固体力学领域却一直缺乏类似的进展(很多固体求解器是GPU acceleration而非完全GPU Compute,因此加速效果有限)。鲁班系统近年来专注【GPU Compute + 科学计算】领域研究与积累,开发了鲁班科学计算GPU通用加速底座,并在固体力学领域、系统仿真等领域进行了开发实践,取得了初步进展。
一、物理仿真求解加速(结构力学仿真)
例如,利用最新的GPU服务器,鲁班在结构力学领域克服多个非线性算法难题,获得了可类比头部商软在流体领域的GPU加速比效果,且进一步提升的潜力巨大:
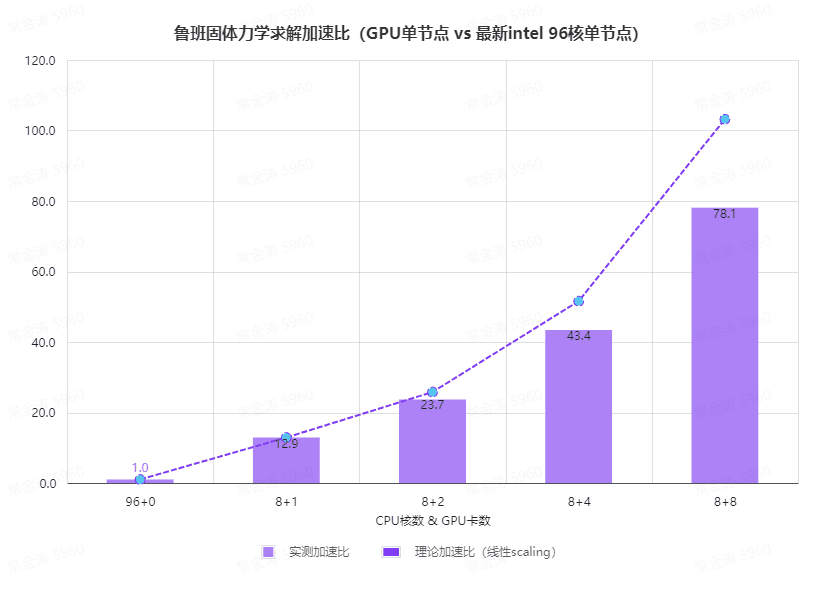
备注:本测试例单元规模为数千万。
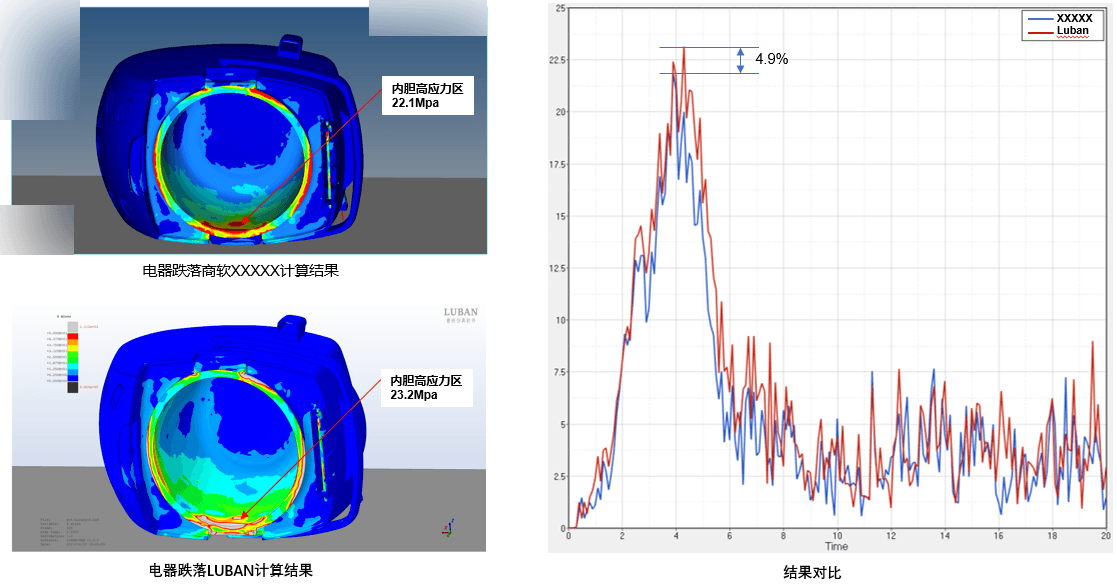
在效率提升的同时保持了高精度的求解结果:
下面的视频展示了超快求解体验:
备注:本案例使用LUBAN CAE 2024初版软件演示,LUBAN正式版求解进展将在后续陆续披露。
相关公开报道链接为:【转载 | 利用 NVIDIA 高性能 GPU,鲁班系统重新定义 CAE 计算效率】
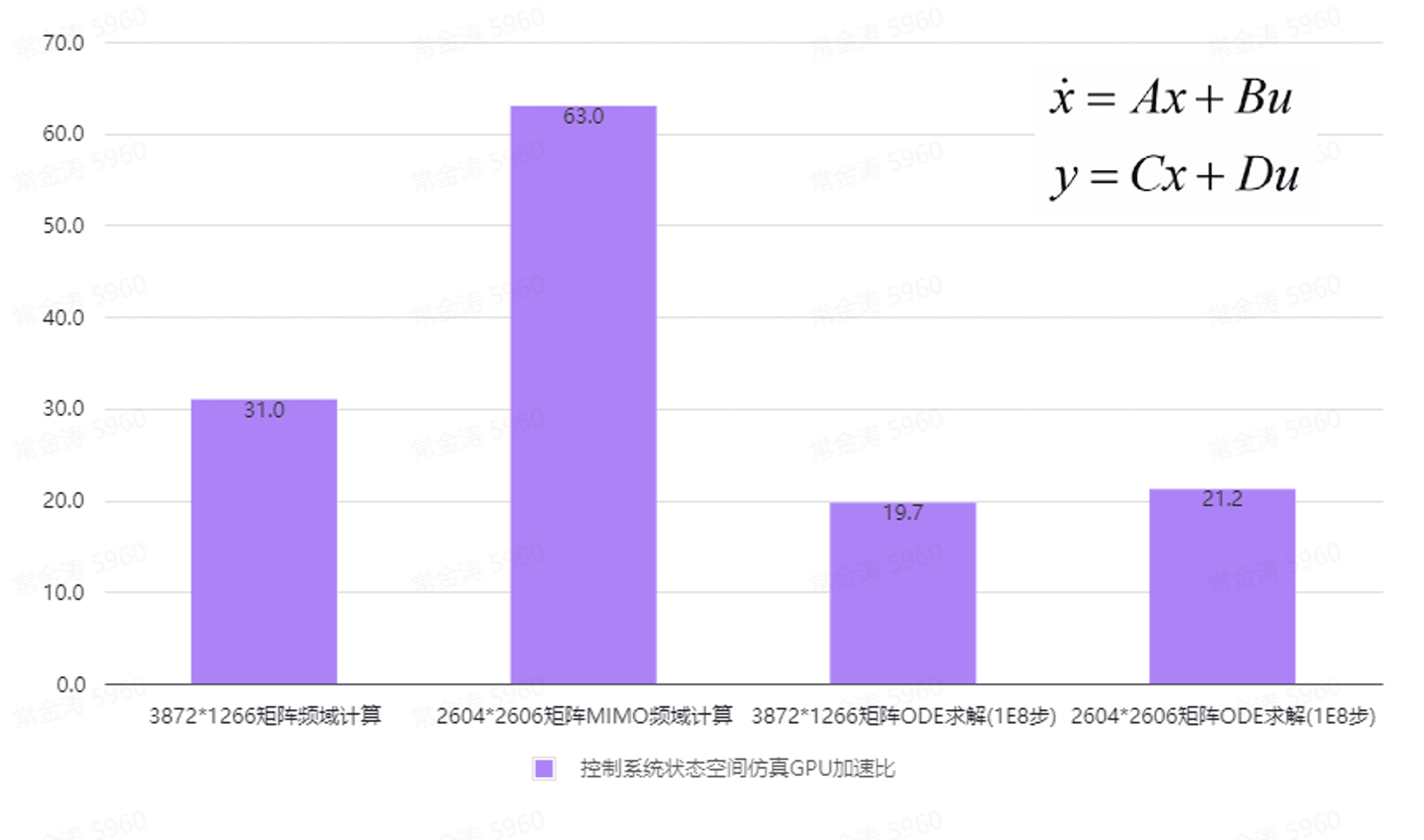
二、控制系统仿真求解加速
基于鲁班科学计算GPU通用加速底座,不仅能够加速物理仿真求解,还能显著提升控制系统仿真求解速度,未来还将支撑更多大型科学计算加速。与商软原生算法相比,LUBAN系统仿真加速库GPU加速效果如下:
未来趋势思考
站在当下的时间节点,我们不妨对仿真技术未来演进的趋势进行预判,引导我们不断取得技术进步:
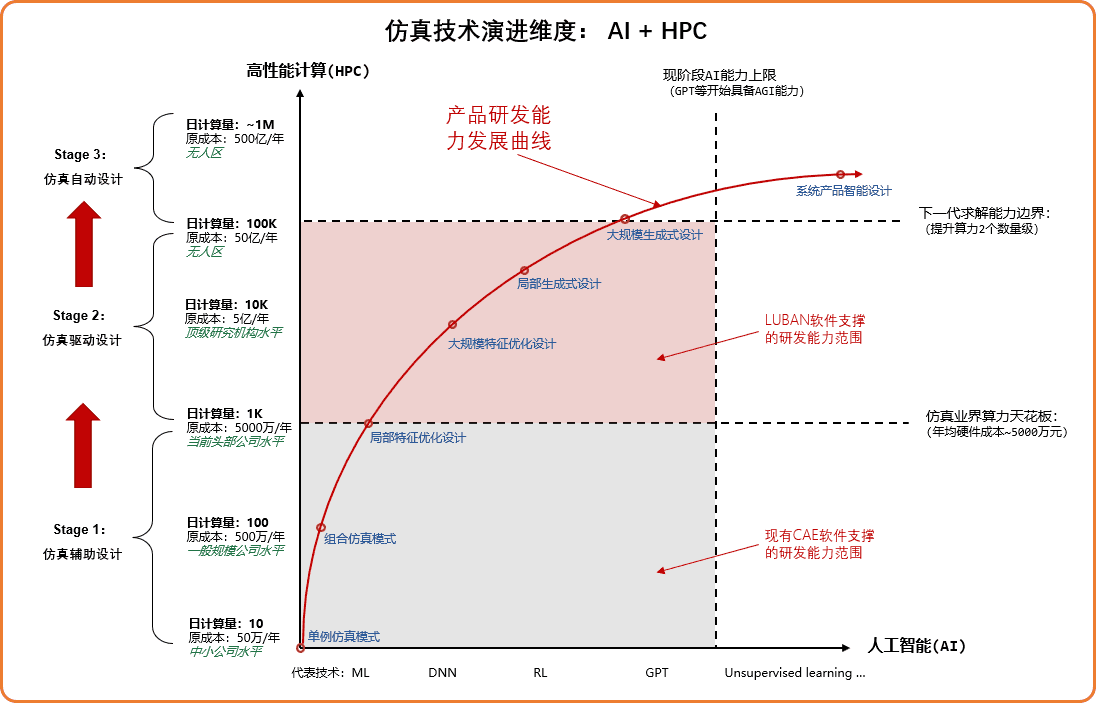
1.仿真计算加速的趋势:充分利用计算硬件的时代红利,将仿真效率提升两个甚至更多数量级,让企业通过更低的硬件成本,支撑更大的仿真数量需求以及更精细的仿真模型。
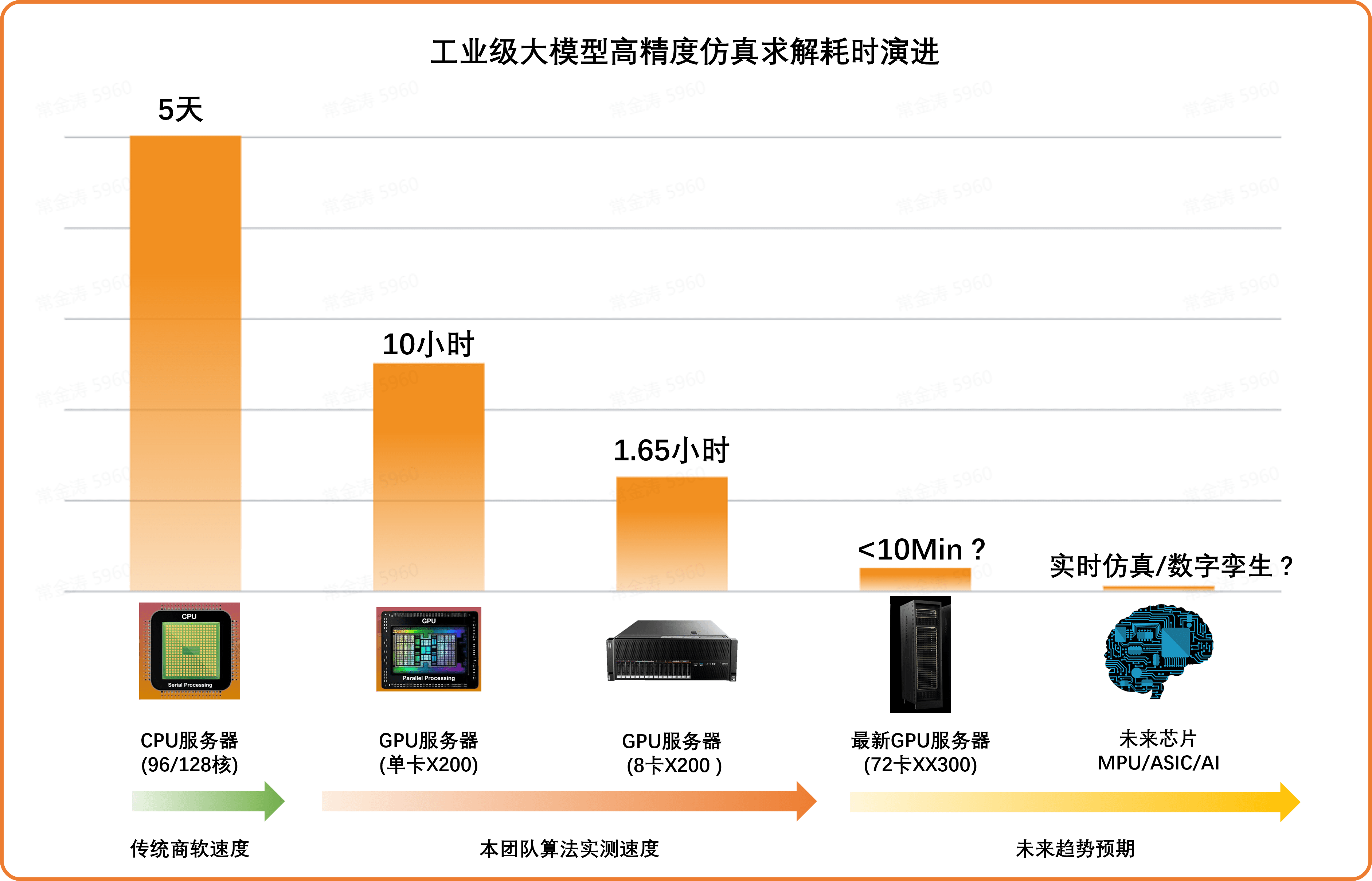
2.AI + Sim发展的趋势:利用效率更高的求解器,在短时间内快速积累大量仿真数据,并交由AI算法调度、决策、演进,逐步在部件级、整机级、系统级产品上实现智能设计的目标。